
人工智能的7個趨勢以及AI如何與操作機器學習協作
時間: 2019-07-22來源: Nisha Talagala

隨著人工智能(AI)變得越來越普遍,每個行業都競相開發人工智能AI解決方案來推進它們的用例,圍繞生產環境部署出現了實際的挑戰。
在之前的文章中:如何從實驗轉向構建生產機器學習應用程序 ,描述了將機器學習(ML)實驗用于生產部署的過程。在這篇后續文章中,概述了有助于用戶簡化和擴展整個機器學習生命周期的七個人工智能行業趨勢。我們將描述每個趨勢,討論為什么它對操作機器學習很重要,以及當企業決定利用趨勢來加速或改進其操作ML實踐時,應該考慮哪些因素。
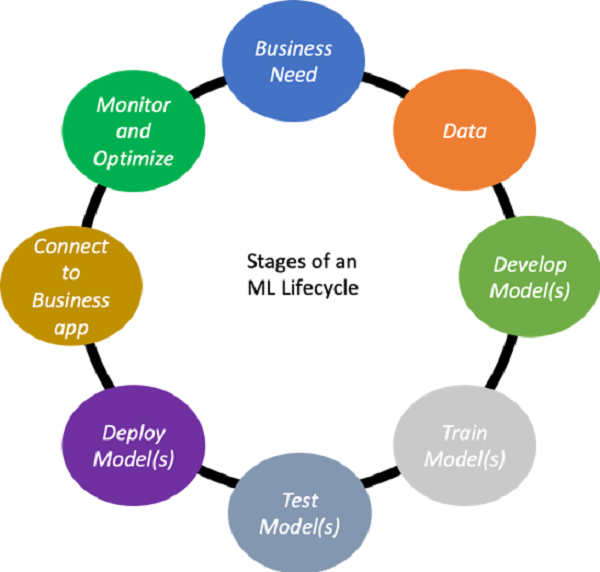
圖1顯示了一個典型的機器學習(ML)生命周期。隨著時間的推移,ML功能相對于業務需求得到進一步優化,這個循環會重復。
趨勢一:數據市場
許多機器學習計劃的第一個挑戰是找到一個可接受的數據集。數據市場試圖解決數據集的短缺,尤其是在醫療和物聯網等關鍵領域,通過提供一個:個人可以分享他們的數據、公司可以使用數據進行人工智能AI和分析的平臺。市場平臺保證了安全性、私密性,并提供了一個經濟模型來激勵參與者。
數據市場可以提供其他難以獲得的豐富的數據,而且市場可以提供數據源并沿襲那些以后管理數據和確保質量所需要的信息。
趨勢二:綜合數據服務
解決數據集短缺的另一個角度是合成數據集市場。機器學習技術的進步已經證明,機器學習本身可以產生真實的數據集來訓練其他ML算法,特別是在深度學習空間中。人工合成數據因其潛力而廣受贊譽,因為相對于能夠訪問大量數據集的大型組織,人工智能AI可以為規模較小的公司提供公平的競爭環境。合成數據可以是真實數據集的匿名版本,也可以是真實數據樣本生成的擴展數據集,還可以是模擬環境,比如用于訓練自動駕駛汽車的虛擬環境。
趨勢三:標簽服務
好的數據集是稀缺的,被標記的好的數據集更加稀缺。為了解決這個問題,出現了一個數據標簽市場,它經常關注特定的數據類型(比如圖像中的對象)。其中一些標簽來自于跨地理區域協調并通過協調軟件管理的人工貼標簽者。公司正在這個領域進行創新,將人工和基于機器學習的標簽結合起來,這是一個有潛力降低純人工標簽成本的趨勢。這一領域的其他創新包括使企業能夠與標識服務提供者直接交互的服務。
趨勢四:自動化機器學習模型
一旦找到合適的數據集并貼上標簽,下一個挑戰就是找到一個好的算法并訓練一個模型。自動化機器學習(AutoML)技術使算法/模型選擇和調優過程自動化,獲取一個輸入數據集,運行大量訓練算法和超參數選項,以選擇建議部署的最終模型。與AutoML相關(并且經常在內部提供),是利用深度特性合成等技術實現的特征工程自動化功能合成。AutoML軟件有時也可以對輸入數據集執行偏差檢測。一些自動解決方案是SaaS產品,而另一些是可下載的軟件,可以在云環境或內部環境中以容器形式運行。
趨勢五:預制容器
對于那些可能正在開發自己模型的人來說,容器是生產部署的一種完善的設計模式,因為它們使任何訓練或推理代碼都能夠在定義良好的可移植和可伸縮的環境中運行。Kubernetes等編制工具進一步支持基于容器的機器學習ML的伸縮性和靈活性。然而,組裝容器可能是一項具有挑戰性的任務,因為必須解決依賴關系,并對整個堆棧進行調優和配置。預先構建的容器市場解決了這個問題,為預先配置的容器提供了預先安裝和配置的必要庫,特別是對于復雜的環境,如GPUs。
趨勢六:模型市場
如果你不想建立或訓練自己的模型,有模型市場。模型市場使客戶能夠購買預先構建的算法,有時還可以購買經過訓練的模型。這些對于以下用例是有用的:
(a)用例是足夠通用的,因此不需要訓練定制模型,也不需要將訓練/推理代碼裝備到定制容器中;
(b)像轉移學習這樣的機制可以用來擴展和定制基本模型;
(c)用戶沒有足夠的訓練數據來建立自己的模型。
在模型市場中,處理數據和訓練一個好的模型這樣重要的工作可以被卸載,使用戶能夠專注于操作化的其他方面。也就是說,模型市場的一個關鍵挑戰是篩選內容,以找到適合您需求的資產。
趨勢七:應用級人工智能服務
最后,對于跨業務存在的常見用例,應用程序級別的人工智能AI服務可以消除對整個操作機器學習ML生命周期的需求。人們可以訂閱執行人工智能任務的終端服務,而不是創建模型、訓練和部署它們。應用級人工智能AI服務包括視覺、視頻分析、自然語言處理(NLP)、表單處理、自然語言翻譯、語音識別、聊天機器人等任務。
好處和注意事項
上述所有趨勢都使用戶能夠簡化或加快一個或多個操作機器學習ML生命周期的各個階段,通過卸載、重用預構建項,或者通過特定階段的自動化。考慮到迭代機器學習ML流程是如何實現的(例如,訓練通常包括數十到數百個實驗),自動化這些流程可以產生更可跟蹤、可重現和可管理的工作流。外包這些任務甚至更容易,尤其是在強化了模型和算法的情況下(除了您自己的環境之外,已經在許多環境中測試過)可以用于基本任務。
也就是說,在您的環境中使用這些服務之前,有幾個因素需要考慮:
1:考慮適用性
并不是所有的趨勢都適用于所有的用例。最普遍適用的趨勢是AutoML,它的應用范圍很廣。類似地,模型市場有非常廣泛的模型和算法可用。數據集市和合成數據集趨向于特定于用例的類,而預構建的容器可以特定于不同的硬件配置(如GPUs),而這些硬件配置又適用于特定的用途。許多數據標簽服務也有特定的用途(比如圖像分類和表單閱讀),但一些咨詢公司確實提供定制的標簽服務。最后,端到端人工智能AI服務非常特定于用例。
2:人工智能信任
隨著更多的ML被部署,人類普遍對黑箱人工智能系統的恐懼表現為對信任的擔憂和對監管力度的加大上。為了從人工智能AI中獲益,企業不僅要考慮生產機器學習ML的機制,還要考慮管理任何客戶社區的關注點。如果不加以解決,這些擔憂可能會在客戶流失、企業出糗、品牌價值損失或法律風險中具體化。
信任是一個復雜而廣泛的主題,但其核心是需要理解和解釋機器學習ML,并確信ML在預期的參數范圍內正確運行,不受惡意入侵。特別是,生產ML所做的決策應該是可解釋的——即必須提供可信服的解釋。這在諸如GDPR的解釋權條款等法規中變得越來越有必要。可解釋性與公平性密切相關——需要確信人工智能AI不是無意或故意做出有偏見的決策。例如,亞馬遜(Amazon)Rekognition等人工智能AI服務也因存在偏見而受到關注。
由于上面提到的幾乎所有趨勢都涉及到將機器學習ML生命周期的某些方面卸載或“外包”給第三方或自動化系統,因此需要在每個階段進行額外的了解,以確保最終的生產生命周期能夠交付信任的核心原則。這包括了解所部署的算法,用于訓練它們的數據集是否沒有偏見,等等。這些需求不會改變生命周期本身,但是需要付出額外的努力來確保正確的沿襲跟蹤、配置跟蹤和診斷報告。
考慮3:可診斷性和運營管理
無論機器學習ML生命周期的組件來自何處,您的企業都將負責管理和維護ML服務在其生命周期中的健康狀態(除了人工智能趨勢7中完全外包的服務之外)。
如果是這樣,數據科學家和工程師必須了解正在部署的模型、用于訓練模型的數據集以及這些模型的預期安全操作參數。由于許多服務和市場都是新生的,所以目前還沒有標準化。用戶有責任理解他們所使用的服務,并確保服務能夠與生命周期的其余部分一起得到充分的管理。
(編譯自:7 Artificial Intelligence Trends and How They Work With Operational Machine Learning,作者: Nisha Talagala)