
Salesforce AI新研究,翻譯中的情境化詞向量
時間: 2017-08-08來源: 怡海軟件

Salesforce Einstein發布以來究竟做了哪些事情,做了哪些高科技含量的事情,下面我們就來一起看一看Salesforce Einstein 在自然語言處理領域的新研究吧。
Salesforce 在去年成立新部門 Salesforce Research,專門處理關于深度學習、自然語言處理,和計算機視覺辨識技術的研究,協助用在 Salesforce 的產品線上。其人工智能服務愛因斯坦AI (Einstein AI),將與他們既有的云端服務結合,提供更好的服務。近期,他們發布了新的自然語言處理成果,我們一起來看看。
現如今,自然語言處理(NLP)找到一個很好的實現方法,通過對單個單詞的理解以植入新的神經網絡,但是該領域還沒有找到一種方法可以初始化新網絡,理解這些單詞與其他單詞之間的關系。我們的研究打算利用已經學會了如何使文本情境化的網絡,從而使新的神經網絡能夠學習理解自然語言的其他部分。
對于NLP中的大多數問題來說,理解情境至關重要。翻譯模型需要了解英語句子中的單詞是如何協同工作的,從而生成德語翻譯。摘要模型需要通曉上下文,從而知道哪些詞是更重要的。執行情緒分析的模型需要了解如何能夠掌握那些改變他人表達情緒的關鍵詞。問答模型依賴于對一個問題中的詞語如何改變一個文檔中詞語重要性的理解。由于這些模型中的每一個都需要理解情境是如何影響單詞的含義的,因此每個模型都可以通過與已經學習如何情境化單詞的模型相結合來獲益。
一條通往NLP Imagenet-CNN的路徑
在找尋可重復使用的表征方面,顯然計算機視覺已經比NLP取得了更大的成功。在大圖像分類數據集(ImageNet)上訓練的深度卷積神經網絡(CNN)經常用作其他模型中的組件。為了更好地對圖像進行分類,CNN通過逐漸構建像素是如何與其他像素相關的更為復雜的理解,來學習圖像的表征。諸如圖像標注、面部識別和目標檢測等模型處理任務都可以從這些表征開始,而不需要從頭開始。NLP應該能夠做一些和單詞及其語境類似的事情。
我們可以教一個神經網絡如何在情境中理解單詞。首先,教它如何將英語翻譯成德語;然后,我們將以一種方式來展示我們可以重復使用這個網絡,即計算機視覺中在ImageNet上進行訓練的CNN的重用。我們通過將網絡的輸出,即情境向量(context vectors (CoVe))作為學習其他NLP任務的新網絡的輸入來實現。在我們的實驗中,將CoVe提供給這些新網絡總是能夠提高其性能,所以我們很高興發布生成CoVe的已訓練網絡,以便于進一步探索NLP中的可重用表征。
詞向量
可以說今天的大多數用于NLP的深度學習模式主要是依靠用詞向量來表征單個單詞的含義。而對于那些不熟悉這個概念的人來說,所有這一切只不過意味著我們將語言中的每個單詞與一個稱為向量的數字列表相關聯在一起。

圖1:在深度學習中,常常將單詞表征為向量。深度學習模型不是像讀文本般讀取序列單詞,而是讀取單詞向量的序列。
預訓練詞向量
有時,在為特定任務訓練模型之前,常常將詞向量初始化為隨機數列表,但是用諸如word2vec、GloVe或FastText之類的方法來初始化模型的詞向量也是很常見的。這些方法中的每一種都定義了一種學習具有有用屬性的詞向量的方法。前兩種假說認為,至少有一部分單詞的含義與它的用法是相關的。
word2vec通過訓練一個模型來處理一個單詞并預測一個本地情境窗口;模型看到一個單詞,并試圖預測在其周圍的單詞。
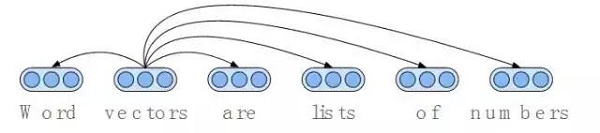
圖2:像word2vec和GloVe這樣的算法產生的詞向量與在自然語言中經常出現的詞向量是相關的。這樣一來,“(vector)向量”的向量意味著出現在諸如“lists”、“of”以及“numbers”這類單詞周圍的單詞“vector”。
GloVe采取類似的方法,但它還明確地添加了關于每個單詞與其他每個單詞發生頻率的統計信息。在這兩種情況下,每個單詞都由相應的詞向量表示,并且訓練強制詞向量以與自然語言中單詞的使用相關聯的方式相互關聯。
預訓詞向量的突現屬性
如果將這些詞向量視為空間中的點,我們可以從中看到一種令人著迷的緊密關系,從而讓人聯想到單詞之間的語義關系。
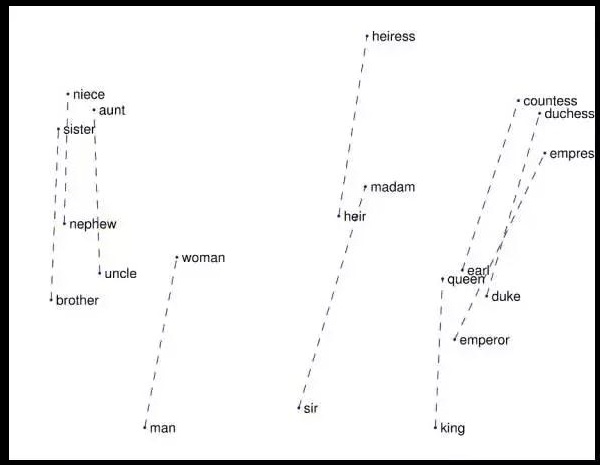
圖3:捕獲到的男性—女性單詞對之間的向量差異(Pennington等人在2014提出的觀點)。
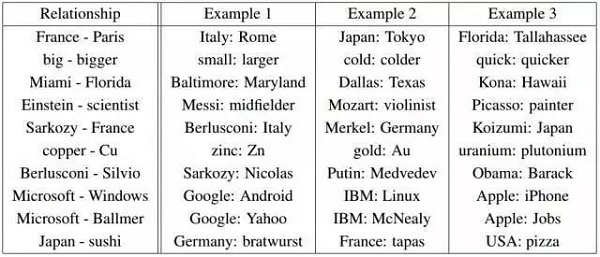
圖4:對于關系a-b,c:d表示c +(a-b)產生更接近d的向量(Mikolov等人于2013年提出觀點)。
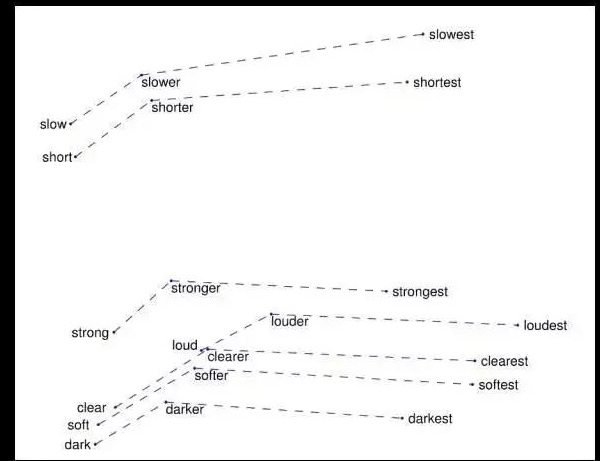
圖5:捕獲到的比較和較高級關系之間的向量差異(Pennington等人于2014提出的觀點)。
很快就發現,在為目標任務初始化一個模型時,如果用word2vec或GloVe所定義的用于中級任務的預訓練詞向量進行訓練,將會使模型在目標任務上更加具有優勢。因此,由word2vec和GloVe生成的詞向量在NLP的許多任務中找到了廣泛的實驗方法。
隱藏向量
這些預訓練的詞向量表現出有趣的屬性,并提供了對隨機初始化的詞矢量的性能增益。但是正如上面所敘述的那樣,單詞很少獨立出現。使用預訓練詞向量的模型必須學習如何使用它們。我們的工作是通過對中級任務進行訓練,找到一種用于改進詞向量情境化的隨機初始化方法,從而提取詞矢量。
編碼器
情境化詞向量的一種常見方法是使用一個循環神經網絡(RNN)。RNN是一種處理可變長度的向量序列的深度學習模型。這使得它們適合于處理詞向量的序列。我們使用的是一種稱為長短期記憶網絡(LSTM)的特定類型的RNN,從而更好地處理長序列。在處理的每個步驟中,LSTM接收一個詞向量,并輸出一個稱為隱藏向量的新向量。該過程通常被稱為編碼序列,并且將執行編碼的神經網絡稱為編碼器。
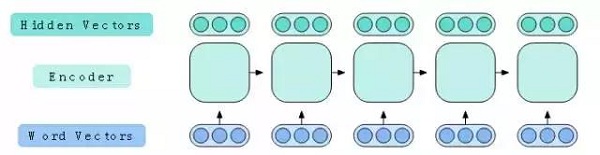
圖6:LSTM編碼器接收一個詞矢量序列并輸出一個隱藏向量序列。
雙向編碼器
這些隱藏的向量不包含序列中稍后出現的單詞的信息,但這一點很容易進行補救。我們可以反向運行一個LSTM從而獲得一些反向輸出向量,并且我們可以將它們與正向LSTM的輸出向量相連,以獲得更有用的隱藏向量。我們把這對正向和反向的LSTM當做一個單元,它通常被稱為雙向LSTM。它接收一個詞向量序列,運行正向和反向LSTM,連接對應于相同輸入的輸出,并返回所得到的隱藏向量的結果序列。
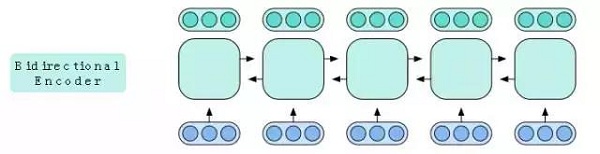
圖7:雙向編碼器包含每個單詞前后的信息。
我們使用一組兩個雙向LSTM作為編碼器。第一個雙向LSTM處理其整個序列,然后將輸出傳遞給第二個。
機器翻譯中的隱藏向量
正如預訓練的詞向量被證明是許多NLP任務的有效表征一樣,我們期望預訓練我們的編碼器,以便它能夠輸出通用的隱藏向量。為此,我們選擇機器翻譯作為第一個訓練任務。機器翻譯訓練集要遠大于其他大多數NLP任務的翻譯訓練集,翻譯任務的性質似乎具有一種吸引人的屬性,可用于訓練通用情境編碼器,例如,翻譯似乎比文本分類這樣的任務需要更一般的語言理解能力。
解碼器
在實驗中,我們教編碼器如何如何將英語句子翻譯成德語句子,從而教它生成有用的隱藏向量。編碼器為英語句子生成隱藏向量,另一個稱為解碼器的神經網絡在生成德語句子時將引用這些隱藏向量。
正如LSTM是我們編碼器的主干一樣,LSTM在解碼器中也扮演著重要的角色。我們使用一個與編碼器一樣具有兩個層的解碼器LSTM。解碼器LSTM從編碼器的狀態初始化,讀入一個特殊的德語詞向量作為開始,并生成一個解碼器狀態向量。
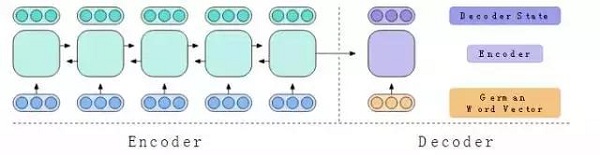
圖8:解碼器使用單向LSTM從輸入詞向量中創建解碼器狀態。
注意
注意機制回顧隱藏向量,以便決定接下來要翻譯英文句子的哪一部分。它使用狀態向量來確定每個隱藏向量的重要性,然后它生成一個新的向量,我們稱之為情境調整狀態(context-adjusted state)來記錄其觀察結果。
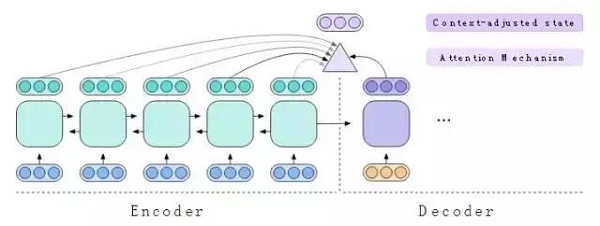
圖9:注意機制使用隱藏狀態和解碼器狀態來生成情境調整狀態。
生成
生成器稍后將查看情境調整狀態以確定要輸出的德語單詞,并且將情境調整狀態傳遞回解碼器,從而使其對已經翻譯的內容與足夠準確的理解。解碼器重復此過程,直到完成翻譯。這是一種標準的注意編碼—解碼器體系結構,用于學習序列的序列任務,如機器翻譯。
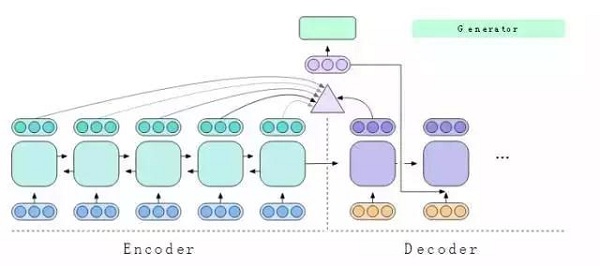
圖10:生成器使用情境調整狀態來選擇輸出單詞。
來自預訓練MT-LSTM的情境向量
當訓練完成后,我們可以提取已訓練的LSTM作為機器翻譯的編碼器。我們將這個已預訓練的LSTM稱為MT-LSTM,并使用它來輸出用于新句子的隱藏向量。當使用這些機器翻譯隱藏向量作為另一個NLP模型的輸入時,我們將它們稱為情境向量(CoVe)。
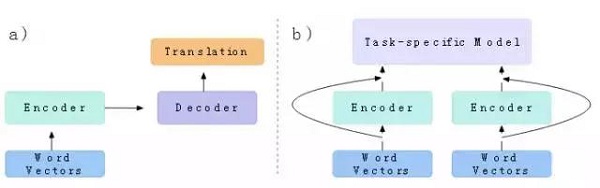
圖11:a)編碼器的訓練b)將其重新用作新模型的一部分
用CoVe進行實驗
我們的實驗探索了使用預訓練的MT-LSTM生成用于文本分類和問答模型的CoVe的優點,但CoVe可以與任何表征其輸入的模型一起作為向量序列。
分類
我們研究兩種不同類型的文本分類任務。第一種,包括情緒分析和問題分類,具有單一的輸入。第二種僅包括蘊涵分類(entailment classification),有兩個輸入。對于這兩種,我們使用雙集中分類網絡(Biattentive Classification Network)。如果只有一個輸入,我們將其復制,假裝有兩個,讓模型知道避免運行冗余計算。而且我們不需要了解BCN理解CoVe的細節以及使用它們的好處。
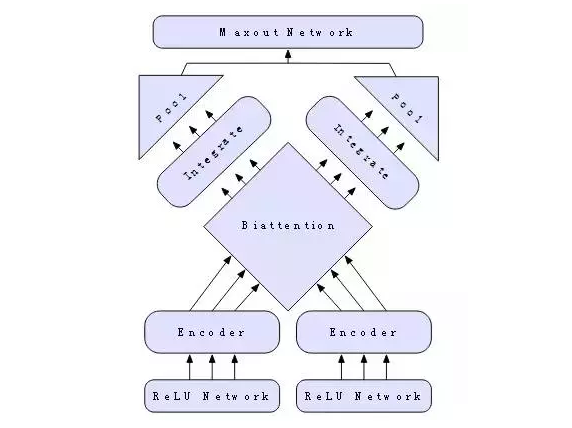
圖12:一個雙集中分類網絡。
問答
我們依靠動態關注網絡(Dynamic Coattention Network)進行問答實驗。為了分析MT數據集對模型學習其他任務性能的影響,我們使用一個稍微修改過的DCN,但實驗測試了整個CoVe和CoVe與字符向量的總體有效性,我們使用udpated DCN +。
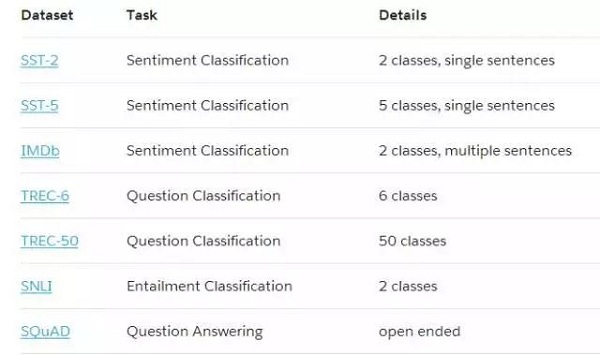
表1:我們實驗中數據集和任務的總結。
GloVe+CoVe
對于每個任務,我們用不同的方式來表征輸入序列。我們可以將每個序列表示為我們訓練的隨機初始化的詞向量序列,我們可以使用GloVe,或者我們可以將GloVe和CoVe一起使用。 在后一種情況下,我們采用GloVe序列,通過預訓練的MT-LSTM運行它,以獲得CoVe序列,并且我們將CoVe序列中的每個向量與GloVe序列中的相應向量相加。不管是MT-LSTM還是GloVe都不是作為分類或問答模型的一部分進行訓練的。
實驗結果表明,在隨機初始化詞向量和單獨使用GloVe的情況下,包括CoVe以及GloVe在內總是能夠提高其性能。
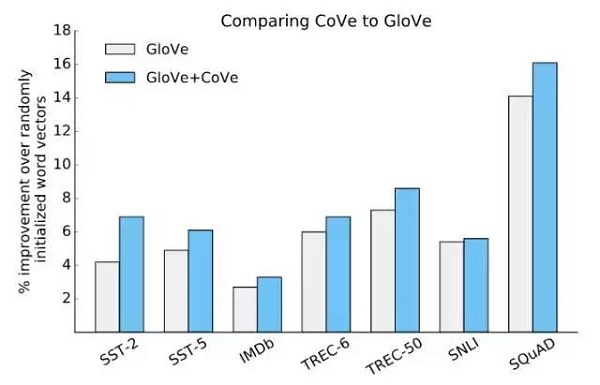
圖13:通過使用GloVe和添加CoVe來驗證性能是否提高。
更多MT→更好CoVe
改變用于訓練MT-LSTM的數據量表明,用更大的數據集進行訓練會導致更高質量的MT-LSTM,在這種情況下,更高的質量意味著使用它來生成CoVe會在分類和問題應答任務上產生更好的性能。
結果表明,用較少的MT訓練數據訓練的MT-lstms所獲得的增益是不顯著的,在某些情況下,使用這些小MT數據集訓練MT-lstm產量,實際上會損害性能。這可能表明使用CoVe的好處來自于使用不平凡的MT-lstm。這也可能表明,MT訓練集的領域對產生的MT-lstm所提供的任務有影響。
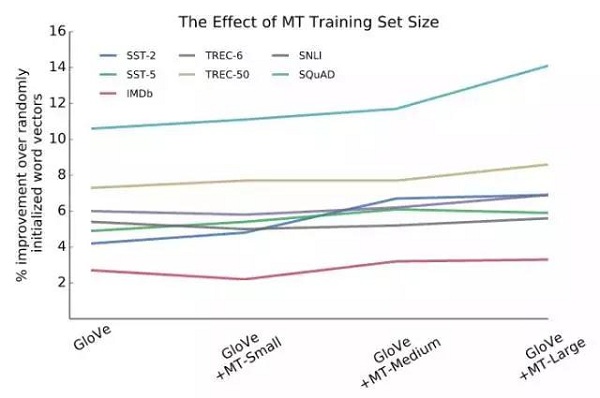
圖14:MT-LSTM的訓練集大小對使用CoVe的模型的驗證性能有明顯的影響。在這里,MT-Small是2016年WMT多模態數據集,MT-Medium是2016年IWSLT訓練集,MT-Large是2017年WMT新聞追蹤訓練集。
CoVe和字符
在這些實驗中,我們嘗試向GloVe和CoVe添加字符向量。結果表明,在某些任務中,字符向量可以與GloVe和CoVe一起工作,以獲得更高的性能。這表明CoVe添加了與字符和單詞級信息相輔相成的信息。
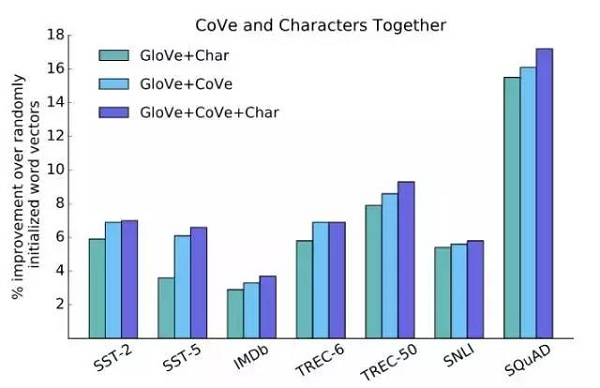
圖15:CoVe與字符向量中存儲的字符級信息互補。
測試性能
我們所有好的模型都使用了GloVe、CoVe和字符向量。我們采用了為每個任務實現更高驗證性能的模型,并在測試集上對這些模型進行了測試。上圖顯示,相較于我們在出發點的表現,添加CoVe始終可以提升我們的模型性能,下表顯示,在我們七個任務中的其中三個里面,在測試集層面,足以推動我們的起始模式向藝術表現的新狀態發展。
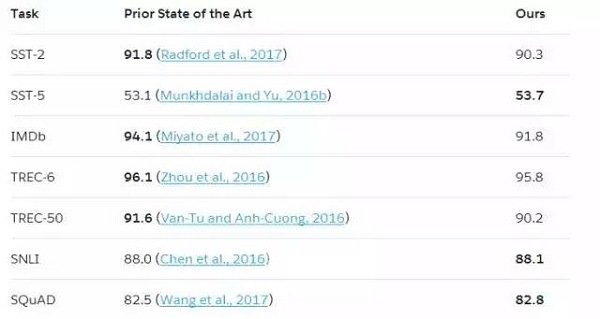
表2:在測試時,測試性能與其他機器學習方法的比較(7/12/17)。
值得注意的是,就像我們使用機器翻譯數據來改進我們的模型一樣,sst-2和IMDb的先進的模型也在使用監督訓練集之外的數據。對于sst-2來說,模型使用了8200萬未標記的Amazon評論,而IMDb的模型使用了50000個未標記的IMDb評論,此外還有22500個監督訓練樣本。這兩種方法都增加了與目標任務相似的數據,而不是我們使用的機器翻譯數據集。這些模型的優越性可能突出顯示了附加數據的種類與附加數據的有益程度之間的聯系。
結論
我們展示了如何訓練一個神經網絡,使其能夠學習情境中單詞的表征,并且我們展示了我們可以使用該網絡的一部分——MT-LSTM,從而幫助網絡學習NLP中的其他任務。在分類和問答模型中,MT-LSTM提供的情境向量或CoVe都無疑推動它們達到更好的性能。我們用于訓練MT-LSTM的數據越多,改進越明顯,這似乎與使用其他形式的預先訓練向量表征所帶來的改進相輔相成。通過將來自GloVe,CoVe和字符向量的信息相結合,我們能夠在各種NLP任務中提高基準模型的性能。